Identify Overfitting Machine Learning Models In Scikit-Learn
STEP 01
To evaluate decision tree performance on train and test sets with different tree depths
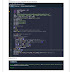
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from matplotlib import pyplot
STEP 02
synthetic classification dataset
from sklearn.datasets import make_classification
STEP 03
define dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1)
STEP 04
summarize the dataset
print(X.shape, y.shape)
STEP 05
To Split a dataset into train and test sets
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
STEP 06
create dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1)
STEP 07
To split into train test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
STEP 08
summarize the shape of the train and test sets
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
STEP 09
define the tree depths to evaluate
values = [i for i in range(1, 51)]
STEP 10
To evaluate a decision tree for each depth for i in values:
1. To configure the model
model = DecisionTreeClassifier(max_depth=i)
2. To fit model on the training dataset
model.fit(X_train, y_train)
3. To evaluate on the train dataset
train_yhat = model.predict(X_train)
train_acc = accuracy_score(y_train, train_yhat)
train_scores.append(train_acc)
4. To evaluate on the test dataset
test_yhat = model.predict(X_test)
test_acc = accuracy_score(y_test, test_yhat)
test_scores.append(test_acc)
5. To summarize progress
print(‘>%d, train: %.3f, test: %.3f’ % (i, train_acc, test_acc))





No comments:
Post a Comment